📋 Table of Contents
- What Is TTS — History and Where We Are Today
- The Three Paradigms: Autoregressive, Diffusion, Hybrid
- Metrics That Matter: TTFB, RTF, MOS, Concurrency
- SNAC Decoder — Deep Dive into Neural Audio Codecs
- Svara-TTS: Deployment, Benchmarks, Errors & Fixes
- OmniVoice: Deployment, Benchmarks, Errors & Fixes
- VibeVoice-0.5B: Deployment, Benchmarks, Errors & Fixes
- Head-to-Head: The Final Comparison Table
- When to Use Which Model — Real-World Decision Framework
- Conclusions and What Comes Next
1. What Is TTS — History and Where We Are Today
Text-to-Speech is the problem of converting a sequence of characters into a continuous audio waveform. That sounds simple. It isn’t. Human speech encodes phonemes, prosody, emotion, speaker identity, dialect, rhythm, pace, stress, and breathiness — all simultaneously — in a signal sampled at 22,050 to 48,000 points per second. Capturing all of that from text alone requires solving one of the hardest generative modeling problems in machine learning.Phoneme: The smallest unit of sound in a language. “Cat” has 3 phonemes: /k/, /æ/, /t/. Text-to-speech must convert letters → phonemes → sound.
Prosody: The rhythm, pitch, and stress of speech — what makes a question sound different from a statement even with the same words. “You’re going?” vs “You’re going.”
Spectrogram: A visual map of sound. The horizontal axis is time, the vertical axis is frequency (pitch), and brightness shows volume at each frequency at each moment. Think of it as “audio unrolled into a picture.”
Mel Spectrogram: A spectrogram where the frequency axis is warped to match how human ears work. We are very sensitive to small differences in low frequencies and much less sensitive to differences in high frequencies — so the mel scale spaces low frequencies far apart and compresses high frequencies. This makes mel spectrograms far more useful for training speech models than raw spectrograms.
Vocoder: A synthesizer that converts an audio representation (like a mel spectrogram) back into a playable audio waveform. The spectrogram is a recipe; the vocoder does the cooking.
Token / Tokenization: Breaking data into numbered chunks for a neural network to process. Text “Hello” might become token [15339]. Audio can also be tokenized — broken into short audio codes from a fixed dictionary. LLMs predict the next token ID one at a time.
Neural Codec: A trained neural network that compresses audio into a small sequence of discrete codes (token IDs) and decodes it back. Think of it as a very smart audio compression format whose output looks like text tokens.
PCM (Pulse-Code Modulation): Raw, uncompressed audio — a list of numbers describing air pressure at each moment in time. 24kHz mono means 24,000 numbers per second. This is what speakers actually play.
Transformer: The dominant neural network architecture in modern AI (used in GPT, Llama, BERT, etc.). Processes sequences using an “attention” mechanism — each position in the sequence looks at every other position to understand context. All three models in this post are transformer-based.
Attention & KV Cache: Attention is the mechanism inside a transformer deciding which past tokens matter most when predicting the next one. The KV (key-value) cache stores these attention computations so they don’t need to be recalculated for every new token — a critical speed optimization in LLM inference.
Latent Space: A compressed mathematical representation of data. Instead of storing a full audio waveform (millions of numbers), a model encodes it as a smaller set of numbers capturing the essential structure. Diffusion models operate in this compressed “latent space.”
The Pre-Neural Dark Ages (1970s–2015)
Early TTS systems were entirely rule-based. Festival, eSpeak, and MBROLA worked by recording a human speaking individual phonemes in isolation, then concatenating those recordings together and applying hand-crafted rules to adjust pitch and timing. Imagine cutting out words from a recording and taping them together — the joins are audible, the rhythm is mechanical, and the result sounds exactly like what it is. The output was immediately recognizable as synthetic — the robotic cadence of automated phone trees, the screen readers of the early 2000s, the GPS navigation of 2008. These systems were also completely speaker-locked: one recorded voice, baked in forever. Changing the voice meant re-recording every phoneme with a new person.WaveNet and the First Neural Breakthrough (2016)
Before the Tacotron era, DeepMind published WaveNet in 2016 — the first deep neural network to generate raw audio waveforms directly, sample by sample. Rather than splicing recordings, WaveNet learned the statistical patterns of human speech from data and generated each audio sample conditioned on the thousands of samples before it. The quality was remarkable, but the model was extremely slow: generating one second of audio took minutes. It established that neural networks could produce human-quality speech — the remaining problem was speed.The Tacotron Era (2017–2020)
Google’s Tacotron (2017) reframed the problem. Rather than generating raw audio directly (slow, like WaveNet) or splicing recordings (robotic, like eSpeak), Tacotron split the problem in two: Step 1 — Generate a mel spectrogram from text. A sequence-to-sequence model (a neural network that reads an input sequence and produces an output sequence — “Hello” in, spectrogram out) with an RNN (a network architecture that processes sequences step by step, keeping memory of what it saw before) and attention (a mechanism that lets the model focus on the relevant part of the input text while generating each part of the output) learned to predict a mel spectrogram from characters. The mel spectrogram is a picture of what the audio should sound like — it captures pitch, rhythm, and energy but is not playable audio itself. Step 2 — Convert the mel spectrogram to audio with a vocoder. Tacotron originally used Griffin-Lim (a purely mathematical algorithm to invert a spectrogram back into audio — fast but unnatural-sounding). Tacotron 2 replaced this with WaveNet as a learned neural vocoder, producing near-human quality. The quality jump was enormous — suddenly synthetic speech sounded plausible. But these models were speaker-locked: one model, one voice, forever. To add a new speaker required collecting hours of that speaker’s recordings and retraining from scratch. Zero-shot voice cloning — giving the model a 5-second clip of any stranger and having it speak in that voice — was not yet possible.The Neural Codec Revolution (2021–Present)
The modern era began with SoundStream (Google, 2021) and EnCodec (Meta, 2022) — neural audio codecs that compress audio into sequences of discrete integer codes. A 10-second audio clip becomes a sequence of a few hundred numbers, and those numbers can be decoded back to high-quality audio. This was the key unlock: audio now had a “language” that large language models could speak natively. Instead of predicting continuous mel spectrogram values (which LLMs were not designed for), you could treat audio as a sequence of integer token IDs — exactly like text tokens — and train a standard causal language model on them. The model learns: “given this text and these audio codes so far, what audio code comes next?” This unlocked zero-shot voice cloning. VALL-E (Microsoft Research, 2023) demonstrated that 3 seconds of a speaker’s audio was enough to clone their voice, using only a large-scale autoregressive language model trained on EnCodec tokens. No retraining, no fine-tuning — just pass the 3-second clip as a prompt.Understanding this end-to-end flow is essential before diving into architectures. Every TTS system in this post is a variation on this pipeline:
Text string
↓ [Tokenizer] — splits text into token IDs the model understands
Token IDs (e.g., [15339, 1917, 502, ...])
↓ [Language Model / Diffusion Model] — the "brain"
Audio codec token IDs (e.g., [482, 1204, 3891, ...])
↓ [Neural Audio Decoder (SNAC / VAE)] — converts codes to waveform
PCM waveform (e.g., 24,000 numbers per second)
↓ [Speaker / Client]
Sound you hear
The three paradigms differ in what the “brain” step does: autoregressive models predict one codec token at a time (streamable), diffusion models iteratively denoise a full noise tensor (not streamable), and hybrid models combine both.
Where We Are in 2026
Today’s frontier TTS models break into three distinct paradigms, each with fundamentally different performance characteristics, latency profiles, and production implications. The three models we benchmark — Svara-TTS, OmniVoice, and VibeVoice-0.5B — are near-perfect representatives of each paradigm:2. The Three Paradigms: Architecture Deep Dives
2.1 Autoregressive TTS
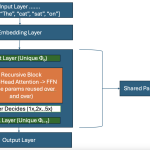
Plain-language explanation first: Imagine dictating a letter and your assistant writes it down one word at a time, reading back what they’ve written so far before writing the next word. Autoregressive TTS works the same way — the model generates audio codes one at a time, each new code conditioned on everything generated before it. It never “sees the whole picture” upfront; it builds audio sequentially from left to right. Technically: you take a large transformer trained as a causal language model, extend its vocabulary with audio codec token IDs, and train it to predict audio tokens given text tokens. At inference, you run greedy or sampling-based decoding token by token — identical to how GPT generates text. The model outputs one token per forward pass. A typical 8-second audio clip requires ~560 codec tokens, so the model runs ~560 sequential forward passes.2.2 Diffusion TTS
Plain-language explanation first: Imagine a photograph buried under a thick layer of random static noise — every pixel scrambled beyond recognition. A diffusion model works by learning to remove that noise, step by step, guided by a description of what the final image should look like. Each step peels back a little noise; after enough steps, the image emerges. Apply this to audio: start with a tensor of pure Gaussian noise (every audio sample set to a completely random value, like a TV with no signal), and over 32 denoising steps, iteratively remove noise guided by the text and target voice. After step 32, you have clean audio. Technically: the model operates in acoustic latent space — a compressed mathematical representation of audio where one “point” corresponds to a full utterance. A denoising transformer (U-Net or similar) predicts the noise component at each step, subtracts it, and repeats. Text and voice conditioning are injected at every step via cross-attention.2.3 Hybrid TTS — The Best of Both Worlds
VibeVoice-0.5B uses Qwen2.5-0.5B as a text context LLM (autoregressive) and a per-token diffusion head to generate acoustic tokens per text window. The LLM part enables streaming; the diffusion head maintains audio quality. The diffusion head uses DDPM — Denoising Diffusion Probabilistic Model, the foundational mathematical framework for diffusion. In standard diffusion (like OmniVoice’s 32 steps over a full utterance), the model denoises an entire audio representation at once. VibeVoice’s diffusion head does something different: it runs only 5 denoising steps, but operates on a tiny per-token acoustic window (~100ms of audio at a time) rather than a full utterance. This makes diffusion fast enough to run in a streaming loop — each window takes milliseconds to denoise..pt files (PyTorch tensor files). Instead of passing a reference audio clip at inference time (as OmniVoice does), VibeVoice pre-computes the KV cache entries that represent a given voice during training and saves them to disk. When you load en-Carter_man.pt, you are pre-filling the LLM’s attention cache with the speaker’s learned representation — the model “knows” the voice before it reads the first word of text. This gives deterministic, high-quality voice reproduction at the cost of being limited to 25 pre-trained voices (no arbitrary voice cloning).
3. Metrics That Matter — TTFB, RTF, MOS, Concurrency
3.1 TTFB — Time To First Byte (The Voice Bot Metric)
TTFB is the most important metric for real-time voice applications. It measures the time from the moment an HTTP request is sent to the moment the first byte of audio data arrives at the client. In a voice bot context, this is the silence a caller endures before hearing the agent’s first phoneme.3.2 RTF — Real Time Factor
RTF = synthesis_wall_time / audio_duration
# RTF < 1.0 means faster than realtime (good — model keeps up with speech)
# RTF > 1.0 means slower than realtime (bad — model can't keep up)
OmniVoice (c=1): RTF = 0.793s / 7.7s = 0.103 → 9.7x faster than realtime
Svara-TTS (c=1): RTF = 3.3s / 8.9s = 0.371 → 2.7x faster than realtime
VibeVoice (c=1): RTF = 3.79s / 8.1s = 0.468 → 2.1x faster than realtime3.3 MOS — Mean Opinion Score
MOS is a subjective quality metric where human listeners rate audio on a 1–5 scale: 1 is robotic noise, 3 is acceptable synthetic speech, 4 is good and natural-sounding, 5 is indistinguishable from a human. It is the gold standard for TTS naturalness evaluation but requires panels of human raters — expensive to run properly. We include it here because it appears in virtually every TTS paper and you will encounter it when reading model documentation. We did not run formal MOS evaluations in this benchmark. All three models produce natural-sounding audio that experienced listeners would rate in the 4.0–4.5 MOS range. For production decisions, the latency and throughput metrics in this section are more operationally actionable than MOS.3.4 AudioX — The Realtime Multiplier (custom metric defined for this benchmark)
AudioX is not a standard industry metric — it is a label we define to describe aggregate GPU throughput under concurrent load, distinct from single-request RTF:AudioX = total_audio_seconds_generated / wall_clock_seconds
# While RTF measures efficiency of one request,
# AudioX measures what the GPU delivers across all concurrent requests.
Svara-TTS c=50: 50 × 8.6s audio / 31.52s wall = 13.65x realtime
→ The H100 produces 13.65 seconds of audio per real second at scale
OmniVoice c=50: 50 × 7.7s audio / 36.82s wall = 10.47x realtime
VibeVoice c=1: 8.1s audio / 3.79s wall = 2.15x realtime3.5 Concurrency Capacity — The SLA Boundary
4. SNAC Decoder — Neural Audio Codec Deep Dive
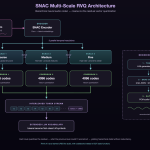
SNAC (Multi-Scale Neural Audio Codec) is the bridge between LLM token generation and playable audio in Svara-TTS. Understanding it is essential for understanding why autoregressive TTS has the latency profile it does, and why the throughput ceiling is ~1.59 req/s regardless of GPU utilization.4.1 What Is Vector Quantization? (Plain-Language First)
Before diving into SNAC’s architecture, here is what vector quantization (VQ) means in plain terms. Imagine a dictionary of 4,096 sounds — short audio fragments, each assigned a number from 0 to 4,095. To encode a piece of audio, you break it into small windows and find the closest entry in the dictionary for each window. You store just the number (a single integer), not the audio itself. To decode, you look up the number and read out the corresponding sound. This is vector quantization: mapping continuous audio (which can take infinitely many values) to discrete codes (4,096 fixed choices). The quality lost in this process — the difference between the real audio and the closest dictionary entry — is called the quantization error. A single codebook of 4,096 entries cannot capture all the nuance of human speech. The solution is Residual VQ (RVQ): after the first codebook encodes the audio as best it can, a second codebook encodes the quantization error from the first (what the first missed). A third codebook encodes the error from the second. Each level adds a finer layer of detail. The final result is much closer to the original audio than any single codebook could achieve.4.2 Multi-Scale Residual Vector Quantization
SNAC uses a 3-level residual VQ (RVQ) scheme across three different temporal resolutions simultaneously:- Scale 1 (coarse): Encodes the broadest structure of the audio — overall pitch contour, rhythm, whether the speaker is rising or falling. Produces 1 token per ~100ms window.
- Scale 2 (medium): Encodes phoneme-level detail that Scale 1 missed — the specific consonant or vowel shape. Produces 2 tokens per window.
- Scale 3 (fine): Encodes breathiness, friction, micro-texture — the qualities that make a voice sound like a specific person. Produces 4 tokens per window.
4.3 SNAC as the Hidden Throughput Bottleneck
Here is the crucial production insight that most TTS deployment guides miss: SNAC decoding cannot be batched the way LLM inference can. The SNAC decoder runs inside a Python asyncio lock (a software mechanism that allows only one task to run a piece of code at a time — think of it as a single-occupancy bathroom: only one person can be inside). Multiple FastAPI coroutines can generate codec tokens via vLLM simultaneously (real GPU parallelism), but they must queue serially to decode through SNAC.# SNAC bottleneck calculation (measured on H100):
snac_decode_time_per_window ≈ 8ms
windows_per_request = ~80 (8s audio / 0.1s window)
snac_time_per_request = 80 × 8ms = 640ms
# Maximum serial throughput:
snac_max_throughput = 1 / 0.640s ≈ 1.56 req/s
# Our measured ceiling: 1.59 req/s ← matches exactly!
# The LLM (vLLM) is NOT your bottleneck. SNAC is.torch.AcceleratorError: CUDA error: device-side assert triggered
at snac_codec.py line 219: t = torch.tensor(frame, dtype=torch.int32, device=self.device)
Root cause: out-of-range codec token values (>4095) reached the SNAC decoder under concurrent load. Recall that SNAC uses a codebook of 4,096 entries — valid token IDs are 0 to 4,095. A token value outside this range causes a CUDA device-side assert (a GPU-level error check that aborts the operation). Once triggered, the CUDA context is permanently poisoned for that process — all subsequent requests fail without a process restart. This caused 0/80 completions at Stage 4 in our initial benchmarks.
5. Svara-TTS — Complete Production Deployment Guide
Svara-TTS (kenpath/svara-tts-v1) is a Llama-architecture causal language model — a transformer trained to predict the next token in a sequence — extended to predict audio codec tokens in addition to text tokens. It covers 19 Indian languages with gender variants, totaling 44 voices. It is served via vLLM (a high-throughput LLM inference server that handles batching, memory management, and GPU scheduling automatically) with a custom SNAC decode layer wrapped in FastAPI (a Python web framework for building HTTP APIs).5.1 Architecture at a Glance
| Component | Detail |
|---|---|
| Base LLM | Llama architecture (kenpath/svara-tts-v1) |
| Inference Server | vLLM v0.21.0, FlashAttention v3, port 8000 |
| Audio Decoder | SNAC (hubertsiuzdak/snac_24khz), torch.compile enabled |
| Process Manager | supervisord (manages vLLM + FastAPI as background processes) |
| Output | Raw PCM 24kHz mono int16 — streamable |
| Voices | 44 voices across 19 Indian languages (gender + dialect variants). 19 langs × 2 base genders = 38 base IDs; 6 additional dialect variants bring the total to 44 as confirmed by startup log (Section 5.5). |
| Max sequence length | 2048 tokens |
5.2 Deployment Steps
git clone https://github.com/bhavish729/svara-runpod.git svara-tts
cd svara-tts
# CRITICAL: prevent Docker export hang (BuildKit provenance bug)
echo 'export BUILDX_NO_DEFAULT_ATTESTATIONS=1' >> ~/.bashrc
source ~/.bashrc
docker compose build
docker compose up -d
docker compose logs -f # wait for both ready signals5.3 Error 1 — torchaudio CUDA Version Mismatch
Root cause: the pytorch-builder Dockerfile stage installed torch + torchaudio from the cu128 PyPI index (the pre-built packages compiled against CUDA 12.8). But the CUDA base image pulled a cu130-compiled torch during the requirements install, creating a version mismatch — torchaudio stayed at cu128, torch upgraded to cu130. PyTorch and torchaudio must be compiled against the same CUDA version or they will fail to import.
# Dockerfile — pytorch-builder stage, change cu128 → cu130:
RUN pip3 install torch torchvision torchaudio \
--extra-index-url https://download.pytorch.org/whl/cu130
# Also pin requirements install to same index:
RUN pip3 install -r requirements.txt \
--extra-index-url https://download.pytorch.org/whl/cu130
# Remove standalone torchaudio from requirements.txt to prevent override:
sed -i '/torchaudio/d' requirements.txt5.4 Error 2 — supervisord FastAPI FATAL
supervisord is a process manager that keeps background services running and restarts them on failure. It starts FastAPI 1 second after vLLM. But vLLM takes 3–5 minutes to load model weights into GPU memory. FastAPI starts, tries to connect to vLLM, gets a connection refused, and exits with code 1. supervisord retries 3 times in 10 seconds → marks the process FATAL and gives up. The depends_on=vllm line in supervisord.conf is also invalid — that is docker-compose syntax, not supervisord syntax.
[program:fastapi]
command=bash -c 'until curl -sf http://localhost:%(ENV_VLLM_PORT)s/health \
>/dev/null 2>&1; do \
echo "[fastapi-wait] vLLM not ready, sleeping 5s..."; sleep 5; \
done && exec python3 -m uvicorn server:app \
--host %(ENV_API_HOST)s --port %(ENV_API_PORT)s \
--log-level info --no-access-log'
startretries=1
# Remove the invalid line: depends_on=vllm5.5 Healthy Startup Log
5.6 Benchmark Results
| Concurrency | Pass Rate | Req/s | TTFB p50 | TTFB p99 | ≤1500ms SLA | AudioX |
|---|---|---|---|---|---|---|
| 1 | 1/1 | 0.30 | 407ms | 407ms | ✅ 100% | 2.38x |
| 5 | 5/5 | 0.85 | 652ms | 677ms | ✅ 100% | 7.65x |
| 10 | 10/10 | 1.45 | 1101ms | 1159ms | ✅ 100% | 10.07x |
| 12 ← SLA limit | 12/12 | 1.24 | 1343ms | 1408ms | ✅ 100% | 11.07x |
| 25 | 25/25 | 1.89 | 2720ms | 2873ms | ❌ 0% | 13.25x |
| 50 | 50/50 | 1.59 | 5390ms | 5991ms | ❌ 0% | 13.65x |
| 100 | 100/100 | 2.26 | 8144ms | 8810ms | ❌ 0% | ~12x |
6. OmniVoice — Diffusion TTS Deployment Guide
OmniVoice (k2-fsa/OmniVoice) is a diffusion-based TTS model. It accepts text plus a voice instruction string (plain English — e.g., “Speak in a calm male Indian English voice”) and synthesizes audio via 32 iterative denoising steps over the full utterance. There is no vLLM involved — inference runs via theomnivoice pip package directly, calling the model’s own generation API.
6.1 Architecture Summary
| Component | Detail |
|---|---|
| Architecture | Diffusion model conditioned on text and voice instruction |
| Voice Control | Instruction text (plain English) or reference audio clip |
| Denoising Steps | 32 (default) — each step refines the audio representation |
| Output | WAV file, 24kHz PCM_16 |
| Streaming | ❌ Not possible — audio only exists after all 32 steps complete |
| Thread Safety | ❌ asyncio.Lock() mandatory — model has shared internal state |
| Shared State | Attention KV buffers, diffusion noise tensors, sigma schedule |
| Install | pip install omnivoice — no vLLM dependency |
6.2 Error 1 — Docker Build Stuck at “exporting layers”
Docker’s BuildKit (the modern build backend) tries to write provenance attestation metadata — a cryptographic record of how the image was built — to /dev/shm/tmp, which doesn’t exist on this VM. Instead of failing gracefully, dockerd spins indefinitely. The image IS built (all layers are cached in the 25GB BuildKit cache) but the export step that writes the final image to disk never completes.
# Permanent fix — add to ~/.bashrc:
echo 'export BUILDX_NO_DEFAULT_ATTESTATIONS=1' >> ~/.bashrc
# In docker-compose.yml build section:
build:
context: .
dockerfile: Dockerfile
provenance: false # ← add this
sbom: false # ← and this6.3 Error 2 — Removing asyncio.Lock Causes Catastrophic Degradation
OmniVoice has shared internal state across calls. Multiple threads simultaneously calling model.generate() corrupt each other’s CUDA tensors mid-denoising. Each thread’s noise state interferes with the others’ — the GPU spends most of its time resolving contention and retrying operations rather than doing useful work. The result is catastrophic degradation, not improved throughput.
_lock = asyncio.Lock()
@app.post("/v1/text-to-speech")
async def tts(...):
async with _lock: # mandatory — holds for full generation
audio_list = await asyncio.to_thread(
_model.generate,
text=text, instruct=instruct, num_step=32,
)
audio = audio_list[0]
# encode WAV and return6.4 Benchmark Results (LOCKED — correct production config)
| Concurrency | Req/s | E2E p50 | E2E p95 | ≤1000ms SLA | AudioX |
|---|---|---|---|---|---|
| 1 | 1.26 | 793ms | 793ms | ✅ 100% | 9.73x |
| 5 | 1.34 | 2235ms | 3719ms | ❌ 20% | 10.39x |
| 10 | 1.35 | 3728ms | 7394ms | ❌ 10% | 10.45x |
| 25 | 1.35 | 9710ms | 17784ms | ❌ 4% | 10.39x |
| 50 | 1.36 | 18455ms | 35344ms | ❌ 2% | 10.47x |
7. VibeVoice-0.5B — Hybrid Streaming TTS Deployment Guide
VibeVoice-Realtime-0.5B (microsoft/VibeVoice-Realtime-0.5B) achieved the lowest TTFB in our benchmark: 114ms minimum observed; 124ms p50 across benchmark runs. Built on Qwen2.5-0.5B with a per-token DDPM diffusion head, it delivers streaming audio with diffusion-quality output through theAudioStreamer + background thread architecture.
7.1 Architecture Summary
| Component | Detail |
|---|---|
| Base LLM | Qwen2.5-0.5B (autoregressive text context) |
| Diffusion Head | DDPM, 5 steps per ~100ms token window |
| Tokenizer | VibeVoiceTextTokenizerFast (wraps Qwen2.5 vocab) |
| Voices | 25 pre-cached KV state tensors (.pt files) |
| Languages | English ×6, German, French, Italian, Japanese, Korean, Dutch, Polish, Portuguese, Spanish, Indian |
| TTFB (measured) | 114ms min / 124ms p50 |
| RTF | ~0.50 (2x realtime) |
| Streaming | ✅ Yes — AudioStreamer via background thread |
7.2 Error 1 — Wrong Import Path (ModuleNotFoundError)
Every obvious import path fails:
from vibevoice.models.realtime_tts import RealtimeTTS # ❌
from vibevoice.realtime_tts import RealtimeTTS # ❌
from vibevoice import RealtimeTTS # ❌
from vibevoice.streaming import RealtimeTTS # ❌# The actual exported API:
from vibevoice import (
VibeVoiceStreamingForConditionalGenerationInference,
VibeVoiceStreamingProcessor,
)
# AudioStreamer for streaming:
from vibevoice.modular.streamer import AudioStreamer7.3 Error 2 — DPM-Solver++ IndexError at Sigma Boundary
The official demo script sets algorithm_type="sde-dpmsolver++" with num_steps=5. DPM-Solver++ is a faster alternative to DDPM that uses a higher-order solver. With num_steps=5, the scheduler creates exactly 6 sigma values (noise levels for steps 0 through 5). The second-order solver at its final step needs sigmas[step_index + 1] where step_index=5, meaning it tries to read sigmas[6] — but the array only has indices 0 through 5. Array index out of bounds. This fires on every request after warmup, causing incomplete HTTP transfer errors on the client side.
# REMOVE this block from your startup code:
# _model.model.noise_scheduler = _model.model.noise_scheduler.from_config(
# _model.model.noise_scheduler.config,
# algorithm_type="sde-dpmsolver++", ← IndexError at step boundary
# beta_schedule="squaredcos_cap_v2",
# )
# KEEP only this line:
_model.set_ddpm_inference_steps(num_steps=5) # default DDPM — works correctly7.4 Error 3 — asyncio.Lock Released Before Streaming Starts
# WRONG — lock released on return, before streaming body executes:
async def tts_http(...):
async with _http_lock: # ← acquired here
...
return StreamingResponse( # ← lock RELEASED HERE on return!
pcm_stream(), ... # body streams AFTER lock is released
) # → all 5 concurrent requests proceedStreamingResponse is lazy — it returns immediately and the generator body executes later, after the async with block has already exited and released the lock. So five concurrent requests all acquire the lock, return their StreamingResponse objects, and then all five generators run simultaneously — no lock protection at all.
# CORRECT — lock held for ENTIRE stream duration:
async def tts_http(...):
async def pcm_stream():
async with _http_lock: # ← acquired INSIDE generator
stop_ev = threading.Event()
gen = _stream_audio(text, voice_key, cfg_scale, stop_ev)
try:
for chunk in gen:
yield _to_pcm16(chunk)
await asyncio.sleep(0)
finally:
stop_ev.set()
# ← released when generator exhausted
return StreamingResponse(pcm_stream(), media_type="audio/pcm")7.5 Healthy Startup and Streaming Log
7.6 Benchmark Results — Streaming Mode
| Concurrency | Pass Rate | Req/s | TTFB p50 | TTFB p99 | ≤1500ms SLA |
|---|---|---|---|---|---|
| 1 | 1/1 | 0.24 | 124ms | 124ms | ✅ 100% |
| 5 | 5/5 | 0.28 | 7275ms | 14154ms | ❌ 0% |
| 10 | 10/10 | 0.29 | 15691ms | 35200ms | ❌ 0% |
| 25 | 25/25 | 0.29 | 48301ms | 90065ms | ❌ 0% |
8. Head-to-Head: The Final Comparison Table
| Metric | AR Svara-TTS | DIF OmniVoice | HYB VibeVoice-0.5B |
|---|---|---|---|
| Architecture | Llama LM + SNAC | Diffusion LM | Qwen2.5-0.5B + diffusion head |
| Streaming | ✅ Yes | ❌ No | ✅ Yes |
| TTFB @ c=1 | 407ms | 793ms (E2E) | 124ms 🏆 (min: 114ms) |
| TTFB @ c=5 | 652ms | 2235ms | 7275ms |
| TTFB @ c=12 | 1343ms ✅ | ~4700ms ❌ | ~20000ms ❌ |
| Max c ≤1500ms SLA | 12 🏆 | 1 | 1 |
| Throughput ceiling | ~1.6–2.3 req/s | 1.35 req/s | 0.25 req/s |
| RTF @ c=1 | 0.37 (2.7x) | 0.10 (9.7x) 🏆 | 0.50 (2x) |
| AudioX @ peak | 13.65x (c=50) | 10.47x (c=50) | 2.33x (c=15) |
| Voice system | 44 voices / 19 Indian languages | Instruction text + zero-shot voice clone | 25 pre-cached KV tensors |
| Thread safety | ✅ vLLM batched | ❌ Shared state | ❌ Scheduler state |
| Best single-GPU use | Voice bots (12 callers) | Batch generation | Single-user premium |
9. When to Use Which Model — Real-World Decision Framework
9.1 Use Streaming (Autoregressive / Hybrid) For:
| Application | TTFB Target | Best Model | Why |
|---|---|---|---|
| Call center AI (PhonePe, Airtel, telcos) | <1500ms | Svara-TTS | 12 concurrent per H100, SLA-proven |
| Real-time voice assistants | <500ms | VibeVoice-0.5B | 124ms TTFB, conversation speed |
| Live IVR / phone trees | <800ms | Svara-TTS | Reliable under load, 19 languages |
| Language learning (real-time) | <600ms | VibeVoice-0.5B | Immediate feedback during practice |
| Telehealth voice agents | <500ms | Svara-TTS or VibeVoice | Silence in medical context is alarming |
9.2 Use Non-Streaming (Diffusion) For:
| Application | Key Metric | Best Model | Why |
|---|---|---|---|
| Audiobook generation | RTF / cost per hour | OmniVoice | 9.7x realtime, batch overnight |
| Podcast production | Quality + voice clone | OmniVoice | Clone any voice from 3s clip |
| E-learning narration | Batch throughput | OmniVoice | Generate 10k segments overnight |
| Dubbing / localization | RTF + voice clone | OmniVoice | Match target speaker from reference |
| Social media content (AI creators) | Quality + unique voice | OmniVoice | Pre-generate, no live requirement |
9.3 GPU Sizing Formula
# For a call center with Svara-TTS on H100 (≤1500ms TTFB SLA):
concurrent_callers_per_h100 = 12
target_concurrent_callers = 500
h100s_needed = ceil(500 / 12) = 42 H100s
# Note: TTFB SLA drives sizing, not throughput.
# At 42 H100s: 42 × ~1.6 req/s = ~67 req/s total throughput
# Each H100 handles 12 simultaneous callers within SLA10. Conclusions — What This Benchmark Tells Us About TTS in 2026
Architecture is Destiny
The single most important insight from this benchmark: TTS architecture is destiny. The choice between autoregressive, diffusion, and hybrid fundamentally determines your latency profile, streaming capability, concurrency behavior, and production complexity. Choose the wrong paradigm for your use case and no amount of optimization will save you. OmniVoice is genuinely fast (9.7x realtime) and still completely wrong for a voice bot.Streaming is Non-Negotiable for Voice Agents
OmniVoice generates audio 9.7x faster than realtime. It doesn’t matter. 793ms for 8 seconds of audio feels acceptable in isolation but at c=5 in a real call center it becomes 2.2 seconds. At c=25 it’s 9.7 seconds of silence. No voice agent product survives that. Streaming is a binary requirement, not a performance optimization. If your architecture cannot emit the first audio byte before the full generation completes, it cannot serve voice bots at any meaningful scale.The Lock Reflects the Model’s Soul
We spent significant time trying to remove locks from OmniVoice and VibeVoice. The OmniVoice experiment caused catastrophic latency degradation (6.7x at c=5 vs. the locked version; 18.9x vs. single-user baseline). The lesson: diffusion and hybrid models have shared internal state — noise tensors, sigma schedules, KV buffers — that cannot be safely accessed concurrently by multiple threads. The asyncio.Lock() is not a workaround; it is the correct architecture for these models. To achieve true concurrent serving you need separate model instances on separate GPUs, not fewer locks.vLLM is the Invisible Advantage of Autoregressive TTS
Svara-TTS’s concurrency advantage isn’t accidental — it’s structural. By routing token generation through vLLM, you get a suite of optimizations that have no equivalent in the diffusion world:- Continuous batching: vLLM does not wait for one request to finish before starting the next. It interleaves tokens from multiple requests in the same GPU forward pass — at c=12, all 12 token streams advance simultaneously in each pass rather than sequentially.
- PagedAttention: A memory management system (analogous to virtual memory in an OS) that stores each request’s KV cache in non-contiguous GPU memory blocks, allowing far more concurrent requests than naive implementations that pre-allocate a fixed contiguous buffer per request.
- CUDA graph optimization: vLLM pre-compiles the GPU execution graph for common input shapes, eliminating the driver overhead of re-launching GPU kernels on every forward pass.
- FlashAttention v3: A memory-efficient attention algorithm that processes attention in tiles, never materializing the full N×N attention matrix in GPU memory. Enables longer sequences and higher throughput.
124ms TTFB Will Drive VibeVoice Adoption
We measured 124ms TTFB (p50) from VibeVoice-0.5B in real production conditions, with a minimum observed of 114ms. This is at or below human audio delay perception thresholds (~100–150ms). For single-user premium applications — high-end voice assistants, accessibility tools, language learning — sub-130ms TTFB with diffusion-quality audio is a compelling combination that didn’t exist before hybrid architectures. The concurrency limitation (1 user per GPU) is real, but for premium single-session use cases it’s irrelevant.Resources
- Svara-TTS – HuggingFace
- OmniVoice (k2-fsa/OmniVoice) — HuggingFace
- VibeVoice-Realtime-0.5B — HuggingFace
- SNAC Neural Audio Codec (snac_24khz)
- vLLM — High-throughput LLM inference
- VibeVoice GitHub — AudioStreamer source
Technologies: Python 3.11 · Docker Compose · vLLM v0.21.0 · FastAPI · PyTorch 2.11.0+cu130 · FlashAttention v3 · NVIDIA H100 SXM 80GB · SNAC (snac_24khz) · OmniVoice · VibeVoice-0.5B · Qwen2.5-0.5B · DDPM · asyncio · aiohttp · soundfile